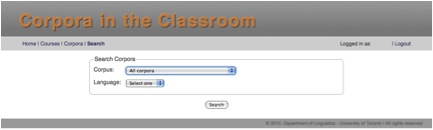
All users can Search the corpora.
You can search a corpus for recordings and transcripts of a particular language (or all languages at once):
We hope to soon have the capability to search for specific text within transcripts, prior to downloading. Currently, however, files must be downloaded prior to searching.
We have 3 corpora available:
The corpus/corpora to search is selected from the Search drop-down menu.
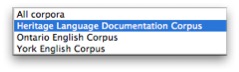
Searches can be limited to data in a particular language. (If no language is selected, data for all languages will be searched.)
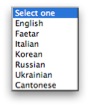 |
Language | Corpus |
| English |
Ontario English Corpus York English Corpus |
|
|
Cantonese Faetar Hungarian Italian Korean Polish Russian Ukrainian |
HerLD Corpus |
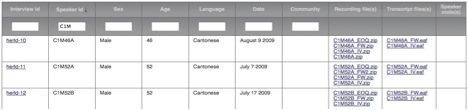
The search results display an Interview ID, a Speaker ID, the Sex and Age of the Speaker, and the Language and Date of the interview recording, the Community (for the English corpora ), and the names of the corresponding Recording File(s) (in .zipped .wav format; mp3 coming soon) and Transcript File(s).
The HerLD corpus has transcript files in .eaf format, to be used with ELAN software.
The Toronto and York corpora have .txt files.
Ex: Searching all languages of the HerLD corpus returns a table like this, providing info about each file:
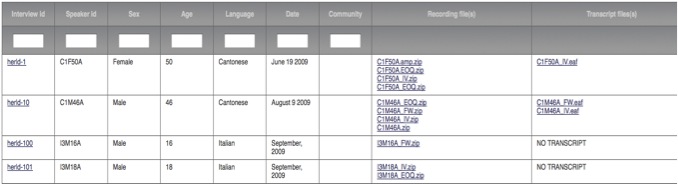
This table can be sorted by any column by clicking on the corresponding header. You can sort by multiple columns simultaneously by holding down the Shift key and clicking a second, third or more column headers.
The blank fields under each header can be used to filter results. For example, entering "C" in the Speaker ID column returns a list of Cantonese speakers. Entering "C1M" returns only male Cantonese speakers from the first generation. [See Speaker ID information.]
Transcriptions and sound files are downloaded by clicking on the appropriate link.
More information about each speaker can be obtained by clicking on their Interview ID.
| [Return to Corpora in the Classroom site.] | Updated May 16, 2013 by Naomi Nagy. |
|---|